Million Song Dataset
“The Million Song Dataset is a freely-available collection of audio features and metadata for a million contemporary popular music tracks” - Including Lyrics, and more
“The Million Song Dataset is a freely-available collection of audio features and metadata for a million contemporary popular music tracks” - Including Lyrics, and more
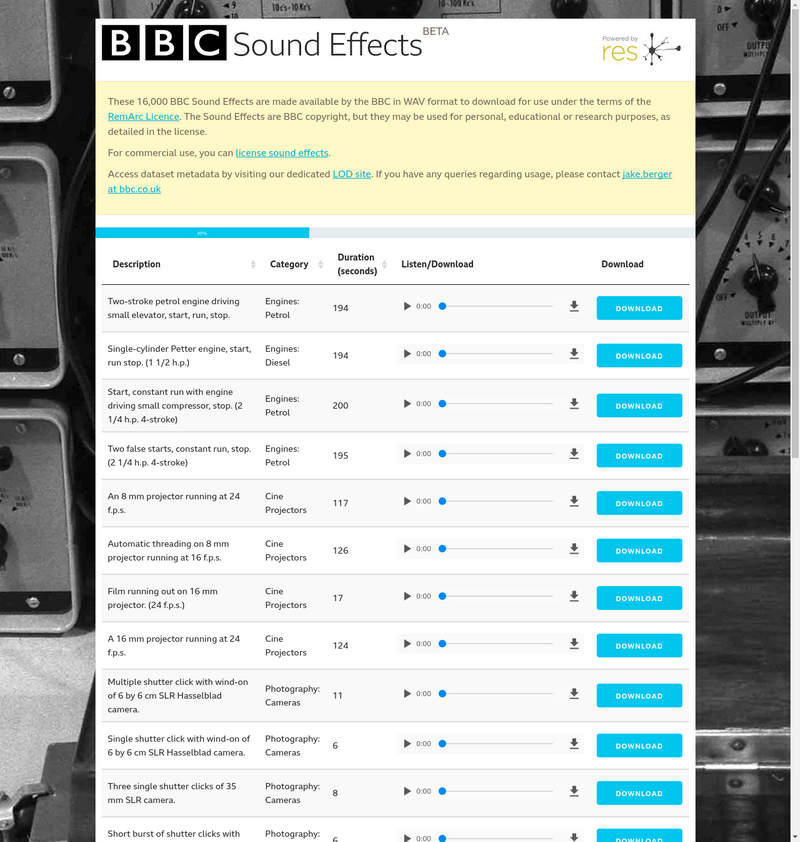
These 16,000 BBC Sound Effects are made available by the BBC in WAV format to download for use under the terms of the RemArc Licence.
Freie und Crowd-gesourcte Stimmerkennungs-Datensätze. Common Voice ist ein öffentlich verfügbarer Sprachdatensatz, der durch Stimmen freiwilliger Mitwirkender auf der ganzen Welt geschaffen wird. Menschen, die Sprachanwendungen erstellen möchten, können den Datensatz verwenden, um Modelle für maschinelles Lernen zu trainieren. Man die Datensätze auch direkt herunterladen unter: https://datacollective.mozillafoundation.org/datasets?q=common+voice

“Wenn Ihr mehr über Datenjournalismus, Transparenz und die Arbeit mit großen Datenbeständen erfahren wollt, könnt ihr das im Chaosradio 243 mit Marcus Richter, Arne Semsrott, Kira Schacht und Michael Kreil.”